



Splunkの技術をベースに開発された「Cisco Data Fabric」や「AI Canvas」を紹介
「データをSplunkへ持ち込む」時代は終わる マシンデータのファブリックを目指すSplunk
2026年01月27日 07時00分更新

Cisco傘下のSplunkは2025年9月、各種データソースを一元的に接続・管理する「Cisco Data Fabric」を発表した。それから4カ月。Cisco Data Fabricは、データのインジェスト(変換)とインデックスのプロセス分離などの技術が盛り込まれ、進化を遂げている。Splunkの技術を基盤とする製品だが、親会社であるCiscoの名前を冠している点でからも分かるとおり、戦略的な位置づけを持つものだ。
2026年1月22日、来日中のSplunk プラットフォーム開発担当VP、セス・ブリックマン氏が、このCisco Data Fabricについて記者向けに説明した。

Splunk プラットフォーム開発担当 VPのセス・ブリックマン(Seth Brickman)氏
マシンデータの爆発的増加、データのサイロ化は「61兆円以上」のコスト
ブリックマン氏はまず、マシンデータの爆発的な増加について説明した。世界には2024年末時点で181ゼタバイト(ZB)のマシンデータが存在し、それが2028年には394ゼタバイトに達すると予測されているという。1ゼタバイトは1000エクサバイト(EB)=100万ペタバイト(PB)=10億テラバイト(TB)であり、仮に1ゼタバイトのHD動画をストリーミング視聴すると3600万年かかる規模だ。
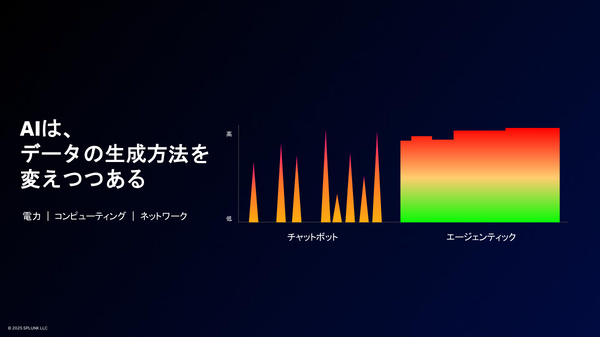
今後数年間に予想される“データ爆発”の背景には、AIエージェントの普及がある。ブリックマン氏は、2028年までに13億のエージェントが稼働するという予測を紹介したうえで、「これまでの生成AIは、チャットボットとして質問を受けたときだけデータを生成していた。しかし(自律的にタスクを実行し続ける)AIエージェントからは、24時間365日データが生成される」と、データ爆発の原因を説明する。
データ量の急増に加えて、「データのサイロ化」も大きな問題だ。IT分野だけでも、セキュリティ、IT、開発、ネットワークの各チームがそれぞれに異なるデータセットを持ち、しかもチーム間での重複もある。ブリックマン氏は、こうしたデータの多様化と複雑化を「データカオス(データの混沌)」と呼び、企業に対して4000億ドル(61.5兆円)以上のコストをもたらすと警鐘を鳴らす。
目指すべき未来像は、そうしたデータカオスを解消したデータ環境だ。ブリックマン氏は次のように語った。
「部門の壁を越えてデータを分析し、膨大なデータから意味を見出せるようになる。チームが効率的にコラボレーションし、ユーザーに影響が出る前に問題を解決する。最終的にデータがAI活用の基盤となる」
“データカオス”を解消する、Cisco Data Fabricの3つの柱
企業がこうしたデータ環境を実現できるように、CiscoとSplunkが提示するのがCisco Data Fabricである。
「Cisco Data Fabricは、Splunkにとって革新的なアーキテクチャだ。データをSplunkに持ち込むのではなく、『データの保存場所にSplunkを持ち込む』ことが実現する」
Cisco Data Fabricのコンセプトは、次の“3つの柱”で構成されている。
(1)AIを活用したデータ管理
(2)統合検索(フェデレーテッドサーチ)と分析
(3)AIネイティブなエクスペリエンスと、AIのためのプラットフォーム

Cisco Data Fabricの“3つの柱”
(1)では、データのオンボードやスキーマ化、データパイプラインの自動修復のためのAIツールを提供する。
(2)は、Splankをデータフェデレーション(複数のデータソースをあたかも単一データソースのように結合する)技術として活用し、「データの保存場所にSplunkを持ち込む」ことを実現する。具体的には「データのインジェストとインデックスのプロセスを分離し、データの保存場所でデータを理解できるようにした」という。これは、AWS、Azure、Google Cloud、Snowflakeなど、マルチクラウドの環境にも対応する。
(3)については、Splunkの検索言語であるSPL(Splunk Processing Language)に対応した新しいAIエージェントを備え、自然言語を使ってSPLクエリを書くことができる。また、Hugging Faceを活用するオープンソース時系列モデルなど、複数のAIツールを提供する。さらに「顧客は自社のマシンデータを使って、独自のAIモデルやエージェントをトレーニングできる」と述べ、AIプラットフォームとしての側面を持つことも強調した。
こうしたデータファブリックの基盤となるのが「Splunk Machine Data Lake」だ。マシンデータ向けのデータレイクであり、「低コストのデータストレージソリューションとして、企業のデータ成熟度に関わらずソリューションを提供する」と説明する。
また、Cisco Data Fabricの特徴として、Ciscoハードウェアとの統合も挙げた。すでにThousand Eyes、Meraki、Ciscoファイアウォールとの統合を発表済みであり、今後も拡充していくという。
「Cisco Data Fabricは、単一プラットフォームの中でインジェストとインデックスの処理を分離させたことで、優れた経済性を提供できる。データサイロを打破し、デジタルフットプリント全体にわたる相関分析のインサイトを提供する」



