



ロードマップでわかる!当世プロセッサー事情 第851回
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ
2025年11月24日 12時00分更新

前回はCPUのロードマップを説明したので、今週はGPUである。といってもコンシューマー向けのRDNAについては連載850回のロードマップにあるように、なにも示されていないに等しいので、説明できるのはInstinctシリーズのロードマップである。
CoWoS-SからCoWoS-Lに切り替わったMI400シリーズ
サーバー向けロードマップは連載829回で説明しているが、そのときからのアップデートは「MI400シリーズの詳細がもう少し明らかになった」「MI500シリーズがロードマップに出現した」というあたりである。
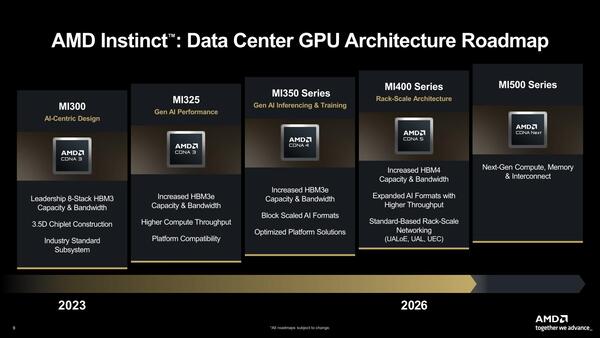
MI500はCDNA 6ではなくCDNA Nextという扱いになっているあたり、あるいはUDNAへの布石と見えるのだが、まだ詳細は不明だ
MI500の話は後で触れるとして、まずMI400シリーズについて。MI300世代はSIoD(Server I/O Die)の上にCCDやGCDなどを3D実装したうえで、そのSIoD同士をインターポーザーで接続するという構成で、その際にシリコン・インターポーザー(CoWoS-S)を利用していたのが、MI400ではCoWoS-Lに切り替わることが明らかにされた。
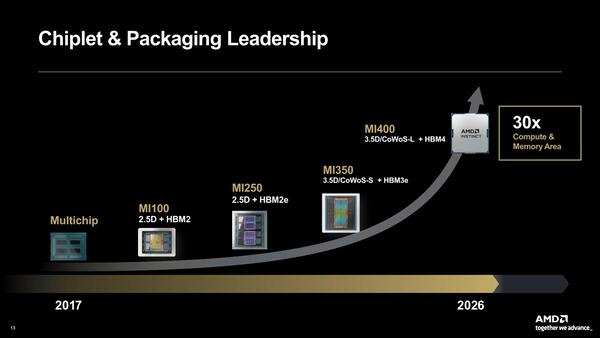
CoWoS-SでもReticle Limitの5.5倍、80×80mmまでは行けたので、MI400はこれより大きくなるという話だ
CoWoS-Lはローカル・シリコン・インターコネクト+RDLインターポーザーという構成になっており、いわばインテルのEMIBとほぼ同じものである。
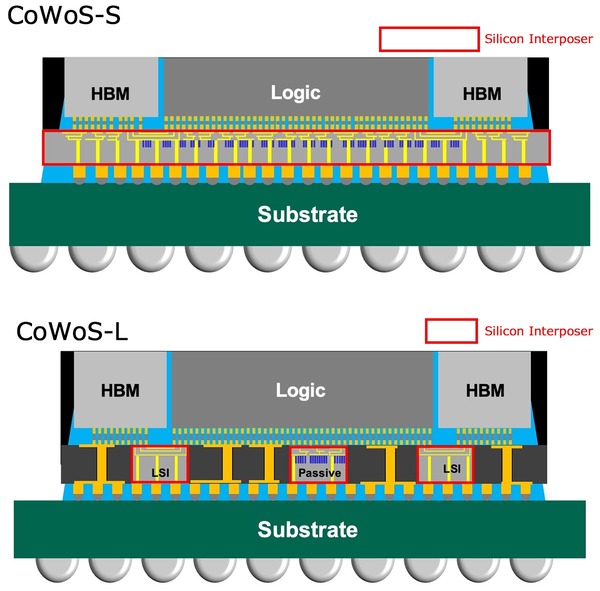
TSMCのCoWoSのページの図より筆者追記。赤枠の部分がインターポーザー。LSI同士の接続以外にパッシブ部品の埋め込みも可能なあたりも同じ
この手の実装で言えば、連載644回で説明したInstinct MI250シリーズのElevated Fanout Bridge 2.5Dがあるのだが、こちらはOSAT(おそらくASEのもの)の協力の元での実装であり、今回はTSMCのソリューションを使った、という点が異なるものだ。
なぜElevated Fanout Bridge 2.5Dを使わなかったのか、もしくは、CoWoS-LがElevated Fanout Bridge 2.5Dより優れているのはどのポイントなのかは残念ながらスライドからは見えてこないので、そのうち機会があればAMDに聞きたいところだ。
MI450の演算性能はMI355Xの倍
そんなMI400シリーズだが、すでにMI450とMI430という2種類の製品があることが判明している。まずMI450であるが、FP4で40PFLOPSという性能と、HBM4で容量432GB、帯域19.6TB/秒という数字が出ている。

Scale up Bandwidthは、キャリアボード内でMI400同士をインフィニティ・ファブリックで接続する際の帯域、Scale out Bandwidthはキャリアボード同士の接続の帯域と考えられる
連載829回でMI350XとMI355Xの性能を示したので、ここから抜き出して比較すると以下のようになる。
| MI350XとMI355Xの性能比較 | ||||||
|---|---|---|---|---|---|---|
| MI350X | MI355X | MI450 | ||||
| FP4性能 | 18.5PF | 20PF | 40PF | |||
| FP8性能 | 9.2PF | 10PF | 20PF | |||
| メモリー容量 | 288GB | 288GB | 432GB | |||
| メモリー帯域 | 8.0TB/秒 | 8.0TB/秒 | 19.6TB/秒 | |||
| スケールアップ帯域 | 1075.2GB/秒 | 1075.2GB/秒 | 3600GB/秒 | |||
| スケールアウト帯域 | 128GB/秒 | 128GB/秒 | 300GB/秒 | |||
演算性能はMI355Xの倍になっており、メモリー容量はMI350X/355Xの36GB(3GB/ダイの12 Hi Stack×8)から432GBに増強され、帯域は19.6TB/秒になった。この数値は、連載830回で紹介した内容と同じであり、この時にはMI400として紹介されたのが今回はMI450とされた、というあたりだろう。
それゆえ、このときのHBM4の構成は12スタックだろうというという推定は現在も有効である。ただ速度の方は計算が間違っていた。転送速度は1万9600GB/秒×8bit÷2048bit÷12≒6380Mbpsで、6.4Gbpsでの転送になるものと思われる。
スケールアップ/スケールアウトの帯域であるが、例えばInstinct MI355Xの場合、ボード内で相互接続するインフィニティ・ファブリックは7リンク@153.6GB/秒、外部に接続するPCIe 5.0 x16が128GB/秒(双方向での合計帯域)となっている。キャリアボードには8枚のInstinct MI355Xが搭載されるので、ある1枚が他の7枚に通信する帯域の合計は153.6×7=1075.2GB/秒というわけだ。
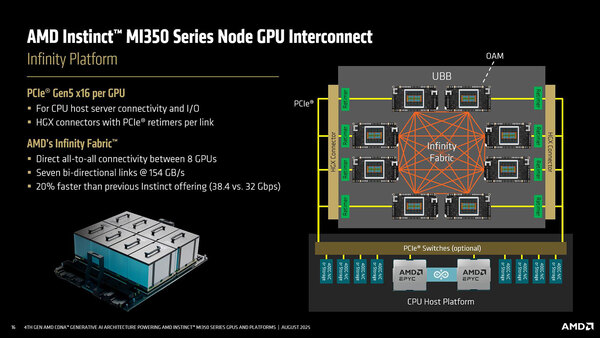
8枚のMI350シリーズがキャリアボード上で1:1の相互接続をしている
Hot Chips 2025におけるAMDの"4th Gen AMD CDNA Generative AI Architecture Powering AMD Instinct MI350 Series GPUs and Platforms"という講演より抜粋
信号速度的に言えば、片方向あたり64bit@9.6Gbps、96bit@6.4Gbps、128bit@4.8Gbpsのいずれかかと思われる。信号速度とバス幅のバランスがいいのは96bit@6.4Gbpsかと思うが、ではMI450はどうか? というのが次の問題。帯域が3倍強になっているのはすさまじいのだが、それがどういう構成になっているのか、が次の問題である。
少なくともMI350シリーズまでの相互接続でこの帯域を実現しようとすると、インフィニティ・ファブリックのリンク1本あたり500GB/秒を超えることになる。どう見てもこれは非現実的である。
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ



/ ACアダプター付属/初期設定済み・届いてすぐ使用可能/ 180日保証")















実機レビュー")
実機レビュー")









+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
/3.1(Gen 1)/3.0/2.0 RUF3-K64GA-BK/N")

")
 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")
 旧東芝メモリ USBフラッシュメモリ 64GB USB3.2 Gen1 最大読出速度100MB/s 国内サポート正規品 KLU366A064G")


