




前回までのHot Chips 2025レポートは、純粋なCPUを紹介してきたが、今回からいろいろ変化球的なものを取り上げていく。まずはインテルのIPU「E2200」である。

写真はIntel IPU Adapter E2100。今回説明するのは後継機種のE2200だ
IPU(Intelligence Processing Unit)そのものの説明は、インテルの初代IPUであるMount Evansの説明を連載634回でしているので今回は割愛したい。要するにインフラ向けプロセッサーである。
データセンター向けのインフラ処理専用プロセッサー
Intel IPU Adapter E2200
Mount EvansはIntel IPU Adapter E2100という名称で2024年から出荷を開始しているが、今回紹介するE2200はその後継機種となる。後継機種なので、当然同様の機能を提供することになる。下の画像が全体のブロック図であるが、これはE2100のブロック図と非常によく似た構造である。ただし性能が大幅に向上している。

E2200の構造。E2100と構造が一緒なのは、基本構成を変える必要はなかった、ということなのだろう。Mount EvansはTSMCのN7での製造だったはずだが、さてE2200はどうなのだろう? 順当に考えればTSMC N5あたりだろう
上の画像を見ても、E2200はE2100の倍のスループットを処理できる性能を持ち合わせているらしいことは容易に想像できる。理由は以下のとおり。
- PCIeのSerDesが、E2100はPCIe Gen4×16なのが、E2200はPCIe Gen5×32に強化されている。
- イーサネットは、E2100が200G MAC/56G SerDesなのに対し、E2200では400G MAC/112G SerDesに速度が倍増している。E2100が50G×4構成の200Gイーサ対応なのに対し、E2200は100G×4の400Gイーサ対応になっている。
- Compute Complexは、E2100が最大16コアのNeoverse N1コア(最大2.5GHz駆動)なのに対し、E2200は最大24コアのNeoverse N2コアに強化されている(動作周波数は未公開)。
- 外部メモリーはE2100が3chのLPDDR4(最大48GB)なのに対し、E2200はLPDDR5-6400×4chに強化されている。
残念ながら今回具体的な性能に迫る数字は公開されなかった。その代わりといってはなんだが、E2100のときにはあまり説明されなかった細かい実装内容の説明があった。
IPUを利用する目的は、単なるイーサネットカードの枠を超えて、さまざまなネットワーク構成を自由に構成できるようにするためのものである。
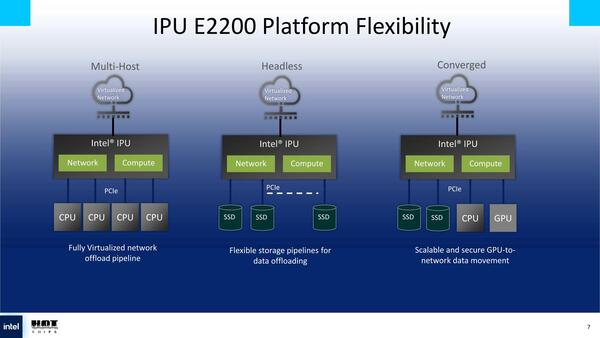
IPUならば、さまざまなネットワーク構成を自由に構成できる。Multi-HostはPCIe x32では2×16構成なので、2つのノードへの接続が精一杯だろう。そのノードがコア数144や288の2ソケットのXeonなら、インスタンス数としては十分ということかもしれない
Multi-Hostは、それこそクラウドサービスのCPUインスタンスに相当するもので、HeadlessはSAN(Storage Area Network)のようなネットワーク・ストレージの構成を可能にする。Convergedが一番スタンダードな使い方だが、要するにコンバージド・ネットワークをIPUを使って簡単に構築できるわけだ。
ここからはもう少し細分化していこう。まずは、記事冒頭の画像で左側に位置するNetwork Subsystemについてだ。Network Subsystemの最上位はPCI Expressで、その下にRDMA/NVMe/LANを処理する専用ブロックが置かれているのはE2100と同じ(もっとも個々のユニットの処理能力は倍増しているだろう)。
その下にあるPacket Processorの構造が下の画像だ。このPacket Processorが、E2100とE2200の核となる部分である。

Packet Processorの構造。インテルにとってPacket Processorはこれが最初ではなく、1998年にDECとの特許訴訟の結果として買収したIXPというNetwork Packet Processorが存在する。ただこれも結局インテルは放棄しており、IXPシリーズはNetronomeという企業がその資産をすべて買収した
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ

")

")
 /Windows11 Pro/MS Office2019/WIFI内蔵/Webカメラ/DVD-ROM/テンキー/Bluetooth/HDMI(Corei5-8265U,メモリ8GB,SSD256GB)")










実機レビュー")
実機レビュー")








 旧東芝メモリ microSD 128GB UHS-I Class10 (最大読出速度100MB/s) Nintendo Switch動作確認済 国内サポート正規品 メーカー保証5年 KLMEA128G")
")
【日本製】USBフラッシュメモリ 32GB USB2.0 国内サポート正規品 KLU202A032GL")

: 11 インチモデル、Liquid Retina ディスプレイ、128GB、Wi-Fi 6、12MP フロント/12MP バックカメラ、Touch ID、一日中使えるバ ッテリー - シルバー")
")

【日本製】SDカード 128GB SDXC UHS-I Class10 読出速度100MB/s 国内正規品 メーカー保証5年 KLNEA128G")
")
/iPad 各種対応(ダークグレー 0.9m)")

