



ロードマップでわかる!当世プロセッサー事情 第847回
国産プロセッサーのPEZY-SC4sが消費電力わずか212Wで高効率99.2%を記録! 次世代省電力チップの決定版に王手
2025年10月27日 12時00分更新

PEZY Computerの最新製品がPEZY-SC4sとして発表された。同社のSCシリーズはやや不遇で、これからという時に技術とまったく関係ないところでケチが付いたことでいろいろビジネスに影響が出た。会社そのものは現在も存在しているし、新製品の開発も続いている。同社に興味がある方はWikipediaの"PEZY Computing"などをご覧いただくのがいいだろう。
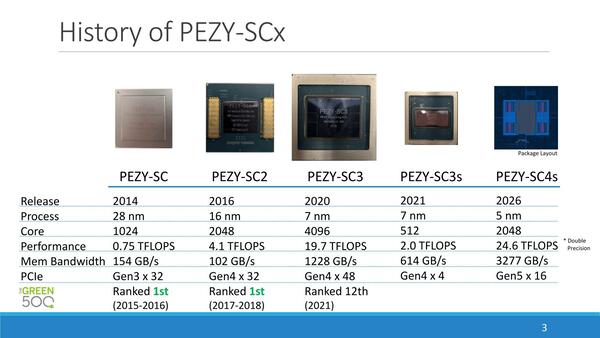
PEZY-SCからSC4sまで。スペックだけ言えばPEZY-SC4でもよさそうなものだが、構造的にはSmall versionにあたるのだろう
世界トップクラスの電力効率を誇る
国産のMIMDメニーコアプロセッサー
PEZY ComputerのSCシリーズのプロセッサーは2014年に最初のPEZY-SCが発表され、これを利用した3システムが2015年6月のGREEN 500のTop 3を独占するという華々しいデビューを飾っている。この時の結果を見ると、理研の菖蒲は7031.4MFlops/W、高エネルギー加速器研究機構の青睡蓮が6841.3MFlops/W、同じく高エネルギー加速器研究機構の睡蓮が6217.9MFlops/Wとなっており、4位に入ったGSI Helmholtz Centerのシステム(5272.1MFlops/W)に結構な差をつけている。
もっとも絶対性能という意味ではTOP500の方を見てみると菖蒲が412.7TFlopsで160位、睡蓮が206.6TFlopsで366位、青睡蓮は193.9TFlopsで392位となっており、1位のTianhe-2(33862.7TFlops)からかなりの差となっている。もちろん絶対性能を求めているシステムではないからこの差は仕方がない。
PEZY-SCの製造プロセスを微細化し、大幅に性能を向上させた製品がPEZY-SC2である。こちらは2017年に発表された。PEZY-SC2をベースにした暁光はJAMSTEC(海洋研究開発機構)に納入され、TOP500で4位、Green 500で1位を獲得した。ただこのリリースが出た直後に齊藤元章社長が詐欺容疑で東京地検に逮捕され、それもあって途端にPEZY-SC2への風当たりが強くなったのは仕方がないことではあるのだが、PEZY-SC2そのものは暁光に加え菖蒲system BもTOP500にランクインしており、2017年11月~2018年11月にGreen 500で1位を維持し続けた。絶対性能という意味でも暁光は19.1PFLOPSを記録しており、実際に使えるシステムであったことは間違いない。
会社代表が変わった同社は、2020年にPEZY-SC3を発表する。こちらはTSMCのN7を利用してコア数を倍増。HBM2を4ch/32GB搭載するほか、外部にDDR4-3200を2ch接続可能となっている。動作周波数は1.2GHzで、消費電力は600Wとされる。発表日は2020年とあるが、リリースされたのは2021年4月のことである。
このサブセットとなるのが、2021年に発表され2022年4月にリリースされたPEZY-SC3sだ。記事冒頭の写真からはわかりにくいが、基本的にはPEZY-SC3の演算器を1/8に減らし、PCIeレーンや管理プロセッサーも削減しつつ、DDR4のI/Fを省いた構成となる。それにも関わらずHBM2を2つ搭載しているのが特徴である。つまり演算器あたりのメモリー帯域やメモリー量はむしろPEZY-SC3の4倍になっているというものである。
実はなぜかPEZYのサイトにはこのPEZY-SC3sの製品情報がないのだが、このPEZY-SC3sを利用した論文は複数(例1、例2、例3、例4)見つけることが可能で、察するにPCIeカードかなにかの形で研究機関向けに販売されている気がする。
PEZY-SC3はPCIe Gen4x48レーン構成で消費電力も470Wと大きいが、PEZY-SC3sはPCIe Gen4x4レーン構成で、動作周波数も1.2GHz→1GHzに落とし、さらに管理プロセッサーはMIPS P6600 1.5GHz×12→1GHz RISC-V×1になっている。簡単に言えば、消費電力は50W前後と予測される。これにより、PCIeカードへの実装が十分可能となっている。
そんなPEZYの最新製品がPEZY-SC4である。といっても基本的なアーキテクチャーそのものは初代のPEZY-SCから変わっていない。PEZY-SCの演算部の基本はMIMDである。ただ同社はこれをSPMD(Single Program, Multi Data)と称している。
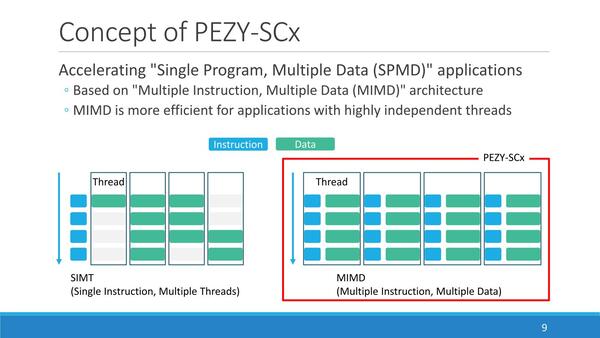
完全なMIMDにすると演算器毎に命令キャッシュが必要になるし、場合によってはプログラムそのものが異なる(≒別のプロセス空間を必要とする)から無駄が多くなることにもなるし、同期を取るのもコストが高くなる。同一のプログラムでスレッドを分けるのは、こうしたケースで効果的である
端的に言えばSIMDは1つの命令で同時に複数のデータを処理できる。それこそMMX/SSE/AVXなどのVector風(本当にVectorかどうかはともかく)演算ユニットであり、対してMIMDはそれぞれの演算ユニットが異なるプログラムに基づき、それぞれ処理する形になる。PEZY-SCはこの中間にあたり、それぞれの演算器は同じプログラムに基づき、独立して処理することになる。あくまでプログラムレベルでの共通性であり、実際に処理される命令そのものは必ずしも同一でないところがポイントだ。
PEZY-SCシリーズの演算の最小単位がPE(Processor Element)である。構造は4段のIn-Order Pipelineであるが、特徴的なのはサイクルごとに異なるスレッドを実行することである。
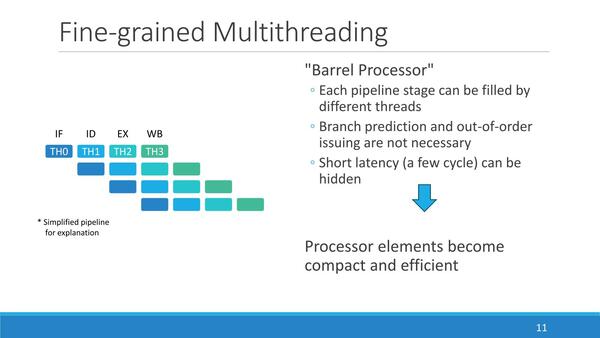
PEZY-SCシリーズは典型的なバレル・プロセッサー構成である。ここにあるように、ブランチ・プレディクション(分岐予測)やメモリーアクセスのレイテンシーをスレッドの切り替えで遮蔽できるというメリットがある一方、パイプラインの外側にスレッド管理のリソースを必要とするのが欠点となる
PEZY-SCシリーズの場合、8スレッドのSMT構成になっており、常に4スレッドが待機状態に置かれている。実行中のスレッドが完了した、あるいはなにかしらの理由で停止した場合、そのスレッドが非アクティブとなり、非アクティブだったスレッドがそれに取って代わられることになる。
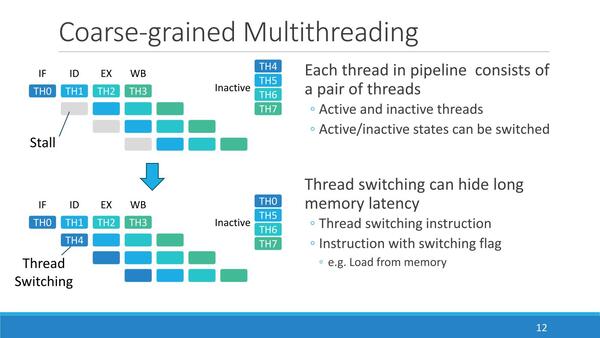
合計8スレッドというのは、どうもBranch Prediction Missの場合でも4サイクルのペナルティで済むので、実行中の4スレッドに加えて、4サイクル分のスレッドを用意すれば常になにかしら実行される、ということから8スレッドになったようだ
こうしたMIMDエンジンを効果的に動かすためには、メモリーアクセスをどうするかがカギになる。PEそのものは独立して動くとして、複数のPEが1つのメモリープールを奪い合うような構成では結局そこがボトルネックになるからだ。PEZY-SCの場合は、おのおののPEに専用の24KBのローカル・メモリー・ストレージを搭載しており、これを利用してメモリーアクセスを実行することになる。
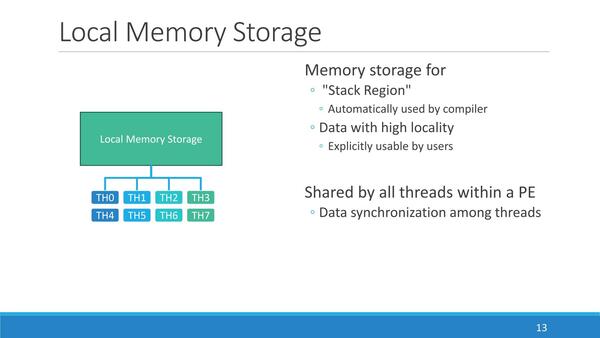
PEに専用の24KBのローカル・メモリー・ストレージを搭載する。ここにStack Regionも設けられている
もちろんこれだけでは足りないので、PEの外にL1キャッシュ/L2キャッシュ/LLCを設け、これで演算結果の書き戻しや新規データの取り込みをカバーすることになる。このL1~L3を利用してPE同士の同期も取れるようになっている。特殊命令としては、このデータ同期以外にリダクションなども用意されているとのことだ。
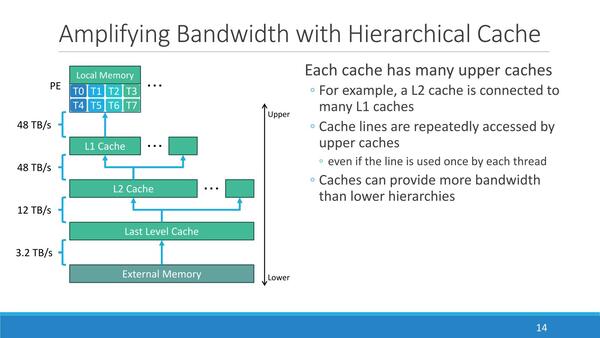
PEの外にL1 D-Cacheが搭載されているのが特徴的。つまりL1そのものはPEでは制御しないことになる。これは次のSync/Flush命令とも絡む話だ
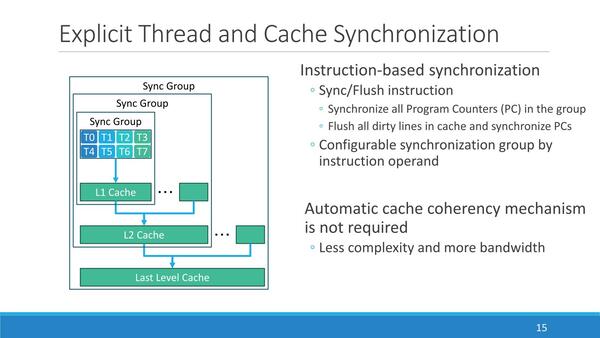
この記述を見る限り、PE同士の同期をどこ(L1/L2/LLC)で取るかはコンパイラー任せになっているように見える
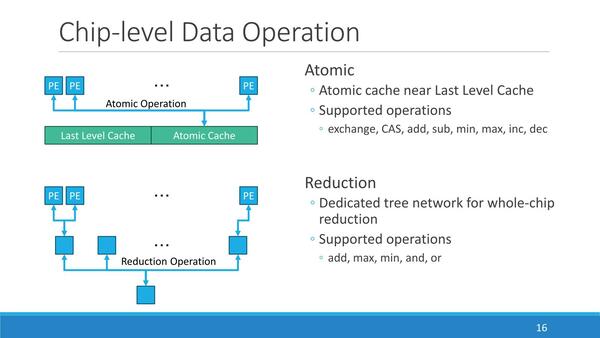
リダクションはAI系の演算にも効果的に見える
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ

")
 FMVWK3E15W_AZ")
")











実機レビュー")
実機レビュー")








 旧東芝メモリ microSD 128GB UHS-I Class10 (最大読出速度100MB/s) Nintendo Switch動作確認済 国内サポート正規品 メーカー保証5年 KLMEA128G")
")
【日本製】USBフラッシュメモリ 32GB USB2.0 国内サポート正規品 KLU202A032GL")

: 11 インチモデル、Liquid Retina ディスプレイ、128GB、Wi-Fi 6、12MP フロント/12MP バックカメラ、Touch ID、一日中使えるバ ッテリー - シルバー")
")

【日本製】SDカード 128GB SDXC UHS-I Class10 読出速度100MB/s 国内正規品 メーカー保証5年 KLNEA128G")
/iPad 各種対応(ダークグレー 0.9m)")


