



ロードマップでわかる!当世プロセッサー事情 第816回
シリコンインターポーザーを使わない限界の信号速度にチャレンジしたIBMのTelum II ISSCC 2025詳報
2025年03月24日 12時00分更新

性能はTelum比で1.3倍
AIアクセラレーターに関してはあまり新情報はないのだが、「自分のチップ内のAIアクセラレーターがBusyで、同じDrawer内の別のチップのAIアクセラレーターが空いている場合、そのAIアクセラレーターを利用できるので、最大192TOPSの性能」というのは、Virtual L4と同じような発想である。

連載790回の画像とあまり差がない。ただチップ右上にCompression Moduleがあることが今回明らかにされた
A-Bus経由で別のDrawerのAIアクセラレーターまで駆動できるかどうかは定かではないが、この書き方からするとVirtual L4に同一Drawer内に限られるようだ。これで足りなければ連載790回で書いたようにSpyreアクセラレーターを使うという形になる。
Telum IIにある個々のコアが下の画像で、パフォーマンス改善に関してはレジスター数の増加、ストアーバッファのライトバック機能の搭載、それと分岐予測の改善が挙げられている。逆に言えばこれと動作周波数向上が主な性能完全の要因とみられ、パイプラインの大幅変更などは特にされていないようだ。

Telum IIにある個々のコア。Area shrinkは主にプロセス微細化によるものと思われる
連載790回でDPUのブロック構造を紹介したが、実際の実装が下の画像だ。個々のクラスターには8つのMCUが配されるという説明があったが、スライドを見ていると最上段に4つ、左右に2つづつ配されているようだ。その真ん中になにが入っているのかは不明だが。
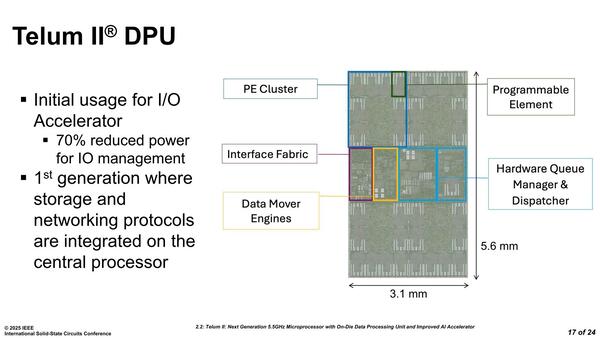
ブロック図でCluster A~Dに当たるのが上下に2つづつ配されたPE Clusterというブロックで、その間にCoherent FabricやHardware Queue Manager&Dispatcher、Data Mover Engineが配される
最後に性能について。下の画像は絶対性能ではなく、同一消費電力当たりのIPCを比較したものであるが、順調に性能を伸ばしているとする。ほぼどの処理でもTelum比で1.3倍ということになっており、世代ごとの性能比としては妥当なところと思われる。
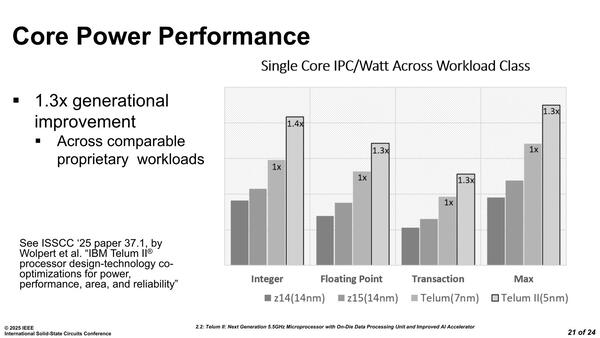
縦軸の単位が不明だが、Telumを1.0とした時には全項目でTelum IIは1.3~1.4倍の性能とされる。ところでMaxは何のテストなのだろう?
問題があるとすればチップあたりのコアの数が10→8に減っていることで、これはDPUを搭載したのが主な要因と思われる。記事冒頭の画像を見返すと、例えばDPUを2つに分割して"Package/Drawer interface"ブロックの両脇に配するなどの方法もありそうに思えるのだが、そうしなかったのはなにか理由があるのだろう。そのあたりの事情を知りたいものである。
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ




/Core i5-7300U(2.6GHz)/8GBメモリ/SSD 256GB/Webカメラ内蔵/13.3インチ (SSD256GB) (整備済み品)")















実機レビュー")
実機レビュー")








+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
")

/3.1(Gen 1)/3.0/2.0 RUF3-K64GA-BK/N")

 PD 急速充電 平型 磁石 マグネット吸着 まとまる 充電ケーブル PD 240W データ転送 480Mbps (ライトブラック, 1m)")
 旧東芝メモリ USBフラッシュメモリ 64GB USB3.2 Gen1 最大読出速度100MB/s 国内サポート正規品 KLU366A064G")
 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")



