




GAAを利用するための3つの困難とその解決策
今回の講演の中では、GAAの製造の難しさについても説明があった。

そもそもNano Sheetの積層という工程そのものがGAAで初めて出てきただけに、いろいろ従来は考えずに済んだような問題が出てくる
まずはトランジスタの製造後に配線層を積層するわけだが、その配線層の積層プロセスの工程が最上位のNano Sheetにダメージを与えるというもの、2つ目がSheet間のメタルゲートの削除が面倒なこと、最後がNano Sheetの幅が広くなると、両端と中央で特性が変わってきてしまうことの3つが言及された。
その問題に対する回答は、当然ながら詳細はまさにGAAを利用するためのノウハウになるので開示はされていないのだが、まず1つ目の問題は“Soft Metal Gate Removal”を利用することで、ゲートからのリーク電流をSF4と比べた場合PMOSは1.58倍だったものを0.28倍に、NMOSでは1.06倍だったものを0.43倍にできたとする。
要するに従来だと最上位のNano SheetがMetal Gate Removableで傷んでしまい、そこからのリークがけっこう多く発生したのが、これでだいぶ緩和された。またMetal Gateの製法にも改良を加えたことで、Nano Sheetの幅に起因する電圧の差も大幅に削減できたとしている。
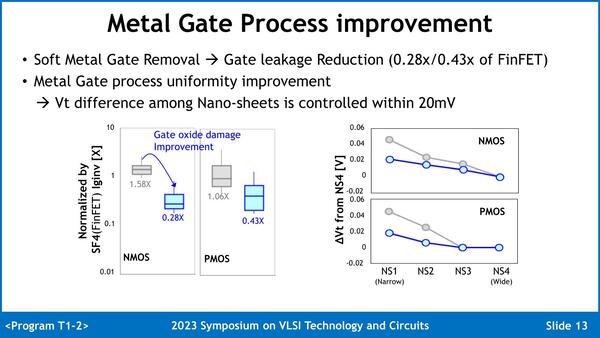
なにをどうソフトにするのかは当然秘密であるが、普通ではCMP(Chemical Mechanical Polish:研磨剤を使って削り取る方式)なので、これを行なう際の圧力を減らしたり研磨剤の特性を変えて削り方を緩やかにしたりするなど、だろうか?
2つ目の問題については、直接的な回答ではないのだが示されたのはMOL(Middle Of Line:中間層)の製造プロセスの改良である。Metal Gateと接続するコンタクト部を、より細長い形状にするとともに、ソース/ドレインの接続部分の組成の最適化をすることで、寄生容量を5%、抵抗を23%削減したとする。
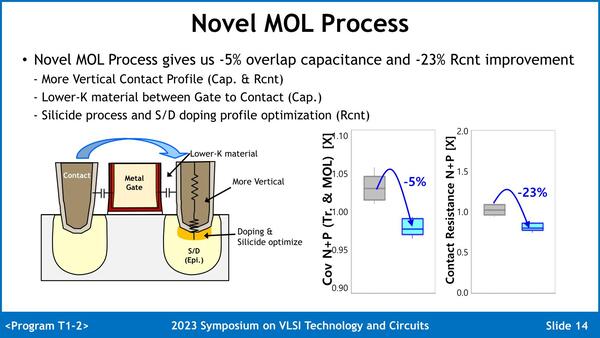
これはSF4比ではなく、最適化前と後の差である
3つ目の問題はDTCO(Design Technology Co-Optimization)の採用で解決した、という。Nano Sheetの構造だけで問題を解決するのではなく、回路側の最適化と組み合わせることで対応したという話で、同じ駆動電流の場合NANDゲートで2.5%、NORゲートで4.5%の高速動作が可能になったとされる。
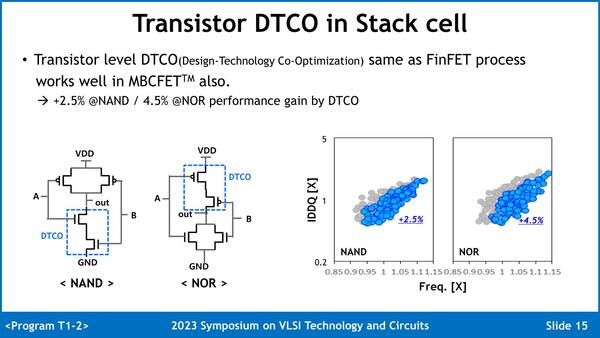
DTCOをかけて、どうNano Sheet内部のバラつきを解消できたのかの説明は当然ながらない(そこが勘所なので、これを公開しても競合メーカーが喜ぶだけである)
ちなみにこうした工夫の結果として、SF4と比較した場合、SF3では特性のバラつきが大きく減ったとされる。これを実現できた理由の1つはチャネルをCMPではなくエピタキシャル成長に切り替えたことがある。ただ確かに特性はそろいそうだが、CMPに比べると時間が掛かりそうな気がするのだが、そのあたりについては言及がなかった。
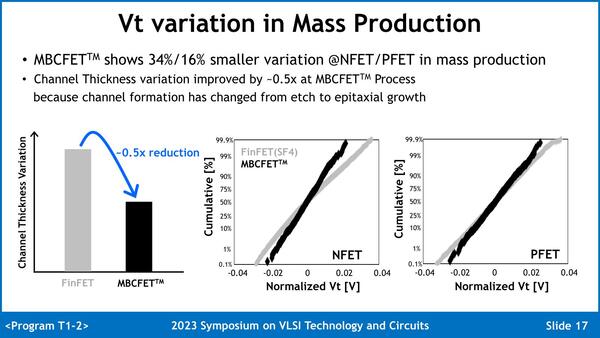
NMOS/PMOSともに電圧のバラつきが±0.04V前後だったものが0.02V前後まで半減しているのがわかる
今回はこのSF3の歩留まりについては説明がなかったし、SF3Eの当初の歩留まりを考えれば、立ち上がりはやや鈍い(プロセス立ち上げ時の歩留まりが低いのは、すでにSamsungの御家芸になっている気もしなくはない)とは思うが、それでも技術的な完成度にはそれなりの自信を感じさせる。
ちなみに今回説明はしないが、T4-1の結論は、BS-PDNを使うことで動作周波数を3.6%向上させ、一方でブロックレベルでのエリアサイズを14.8%削減できるとしている。
動作周波数が上がるのは電流供給能力が改善したことに起因する話で、エリアサイズ削減は電源層を裏面に追いやれることで配線層にゆとりが生まれたためだろう。
インテルはこのBS-PDNをIntel 20AプロセスでGAAと一緒に導入する予定だが、Samsungはより確実性を狙ってかSF3にはBS-PDNは導入しないようだ。ただSF3Pなどは、ひょっとするとSF3+BS-PDNかもしれない。あとは顧客が付くかどうかがSamsungにとって最大の問題かもしれない。
この連載の記事
-
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ -
第849回
PC
d-MatrixのAIプロセッサーCorsairはNVIDIA GB200に匹敵する性能を600Wの消費電力で実現 -
第848回
PC
消えたTofinoの残響 Intel IPU E2200がつなぐイーサネットの未来 -
第847回
PC
国産プロセッサーのPEZY-SC4sが消費電力わずか212Wで高効率99.2%を記録! 次世代省電力チップの決定版に王手 -
第846回
PC
Eコア288基の次世代Xeon「Clearwater Forest」に見る効率設計の極意 インテル CPUロードマップ -
第845回
PC
最大256MB共有キャッシュ対応で大規模処理も快適! Cuzcoが実現する高性能・拡張自在なRISC-Vプロセッサーの秘密 -
第844回
PC
耐量子暗号対応でセキュリティ強化! IBMのPower11が叶えた高信頼性と高速AI推論 -
第843回
PC
NVIDIAとインテルの協業発表によりGB10のCPUをx86に置き換えた新世代AIチップが登場する? -
第842回
PC
双方向8Tbps伝送の次世代光インターコネクト! AyarLabsのTeraPHYがもたらす革新的光通信の詳細 - この連載の一覧へ


 ゲーミングマウスパッド G240 クロス表面 標準サイズ 340×280×1mm マウスパッド G240f 国内正規品")













を2画面搭載するモバイルディスプレー")























の全国大会を見てきた")







")
 旧東芝メモリ microSD 128GB UHS-I Class10 (最大読出速度100MB/s) Nintendo Switch動作確認済 国内サポート正規品 メーカー保証5年 KLMEA128G")


【日本製】USBフラッシュメモリ 32GB USB2.0 国内サポート正規品 KLU202A032GL")

")
+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
")


