




GPUでいうところの4TOPS相当の性能
Perceiveの最初のチップであるERGOは、エッジというよりもエンドポイントに利用できるサイズと消費電力でありながら、高い性能と精度を目指したとするが、この精度と性能に関しては明確な指針が出ている。

高い性能と精度を目指したとする。これだけだと「僕の考えた最強のプロセッサー」になってしまう

YOLOv3とM2Detのどちらもリアルタイムのオブジェクト検出のためのネットワークである
まず精度については、現状データの持ち方(INT1/2/4/8/FP8/BF16/....)よりもネットワークの規模や、そこで利用されるパラメーター数の方が支配的である。
したがって、フルセットのネットワークが稼働する(≒そのネットワークで利用されるパラメーターをオンチップで保持できる)ことが目標となる。また性能に関しては「GPUでいうところの4TOPS相当」という数字が示された。具体的にはYOLOv3で250fps、M2Detで150fpsとされる。
加えて、さまざまなネットワークに対応できる柔軟性と、複数のネットワークを同時に稼働できる容量が必要、という欲張りぶりである。
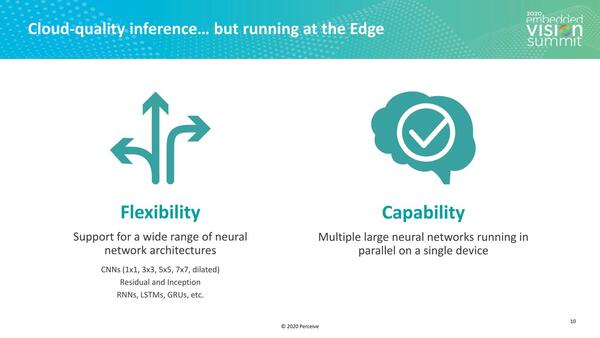
これは例えばAspinityのように、特定のネットワークに絞った実装では不十分、ということである
この複数のネットワークに関しては実際に、イメージングだけ、オーディオだけ、イメージングとオーディオという3種類の実装例が示された。
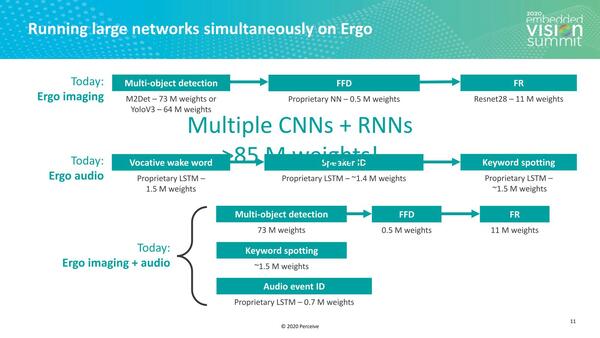
3種類の実装例。FFDはFeature Fused Detectorの意味
こうした複数のネットワークを同時に動かすとなると、処理性能だけでなくパラメーターを搭載するためのメモリーもそれなりに必要になってくる(さもないとパラメーターのロードがボトルネックになる)。
さて、ここまで説明してきておいてなんだが、Perceiveはこれを実現したERGOチップの詳細をまったく明らかにしていない。ERGOチップの内部構造が下の画像で、イメージングI/FとオーディオI/F、IPUとCPUサブシステム、それにNNファブリックがあるが、そのNNファブリックがどんな構成でどのくらいのSRAMが搭載されているか、などは一切未公開なままである。
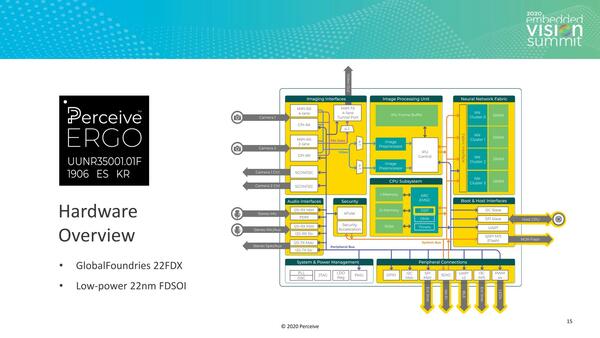
CPUサブシステムはSynopsysのArm EM5Dがベースで、DSPが拡張されている程度。基本的にはシステム制御で、ここでNNを動かしたり音声/画像処理を行なったりはしないと思われる
ただ省電力を実現できた理由の1つとして、Globalfoundriesの22FDXプロセスを利用し、さらにFBB(Forward Body Bias)とRBB(Reverse Body Bias)の両方を利用したとしている。
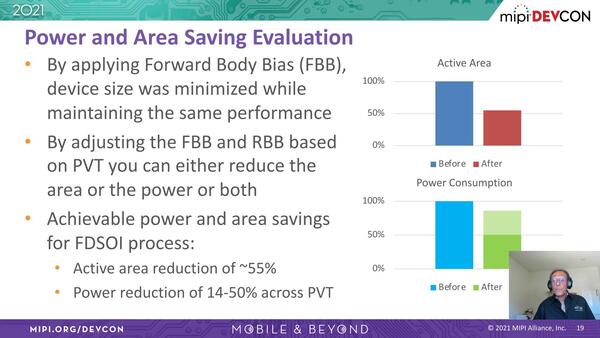
なぜかこの説明はMIPI DevCon 2021で、説明もMIPI I/FをPerceiveに提供したMixelのCEOであるAshraf Takla氏が行なっているが、察するに単にIPを提供しただけでなく、物理設計でも協力していたように思われる
説明によれば、高速動作が必要な部分にFBBを利用することで、アクティブ部分のエリアサイズを最大55%削減、その一方でその他の部分にはRBBを利用してトータルで14~50%の省電力化を図った、としている。
ちなみにチップの外形寸法は7×7mmとされるが、全体の3分の2以上はNNクラスターとSRAMが占めるという説明があった。Globalfoundriesが2017年のVLSI Symposiumで発表した数字によれば、22FDXを利用した場合のSRAM Cellの面積はHD(High Density:高密度)で0.110μm2、HC(High Current:高速)で0.124μm2とされる。
今回の場合はHDを利用しているだろうから、0.110μm2ということになる。パッケージが7×7mmだからといってダイサイズは当然もっと小さいはずだが、具体的な数字は示されていない。
ただ仮に5×5mmとして、そのうち3分の2がNNクラスター+SRAMで、そのSRAMの面積が4分の3くらいだと仮定すると、SRAMのサイズは12~13mm2程度。ざっと計算しても全部で13.5MB程度の容量が精一杯に思われるのだが、これで合計85M以上のパラメーターをどう保持しているのか、はけっこう謎である。
もちろんパラメーターは疎の部分があるので、うまくSparsityを管理して、さらにパラメーター圧縮などを行なっているのかもしれないが。

2つのコネクターに挟まれているのがERGOチップ
このERGOチップはすでに出荷を開始しており、評価ボードも出荷されている。製品の方は定格(250MHz動作)とLow Power(250MHz動作ながらVDDを0.65Vに下げたもの)、High Performance(310MHz動作)の3つが用意されており、性能/消費電力比は圧倒的に高いとしている。
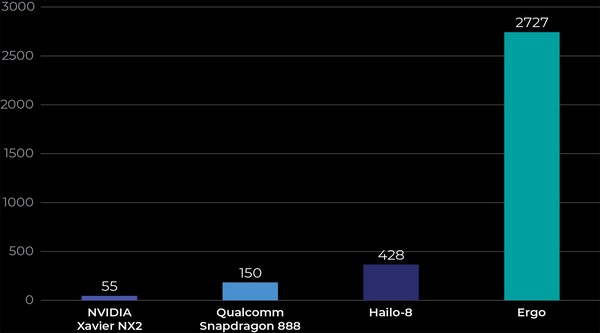
これはResNet-50を実施した場合の性能/消費電力比の比較。ERGOは30fpsでのResNet-50の処理を9mWの消費電力で実現できるとする
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ



/ ACアダプター付属/初期設定済み・届いてすぐ使用可能/ 180日保証")















実機レビュー")
実機レビュー")









+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
/3.1(Gen 1)/3.0/2.0 RUF3-K64GA-BK/N")

")
 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")
 旧東芝メモリ USBフラッシュメモリ 64GB USB3.2 Gen1 最大読出速度100MB/s 国内サポート正規品 KLU366A064G")


