



ロードマップでわかる!当世プロセッサー事情 第685回
メモリーと演算ユニットをほぼ一体化したUntether AIのrunAI200とBoqueria AIプロセッサーの昨今
2022年09月19日 12時00分更新

BoqueriaはrunAI200から大幅性能アップ
演算性能は5倍、電力効率は7倍に
SRAMアレイとPEの詳細が下の画像だ。SRAMセルは、なんと0.4Vの低電圧動作になっているようで、これで消費電力をさらに引き下げる工夫がなされている。
低電圧動作といえばEsperantoのET-SoC-1がやはり0.4V付近での動作を狙っており、Boqueriaのように膨大な量のSRAMを搭載する製品ではこうした配慮が不可欠ということだろうか。

レジスターファイルの扱いなどはrunAI200と大きく変わらない気がするが、T Regはなんの目的なのかは不明。F Regが改称しただけだろうか?
またSIMDの幅が64bitに広げられたようで、さらにデータ型も新たにINT4やFP8、BF16などのサポートが追加されている。これらはより性能を引き上げるのに効果的だろう。この新しく追加されたFP8だが、3種類のフォーマットが選べるとしている。

Eが指数部(Exponent)、Mが仮数部(Mantissa)。Sは符号(Sign)である。範囲重視なら仮数部2桁、精度重視なら仮数部3桁ということらしい
FP8はINT8に比べて最大2倍の効率としているが、仮数部のサイズが半分なら当然そうなることになる。
ちなみにUntether AI社による精度の比較が下の画像である。ResNet-50ではINT8とFP8の精度の差はは0.1%に過ぎず、またBERTベースのSQuAD 1.1でもBF16と比較して1%程度の差でしかないとする。
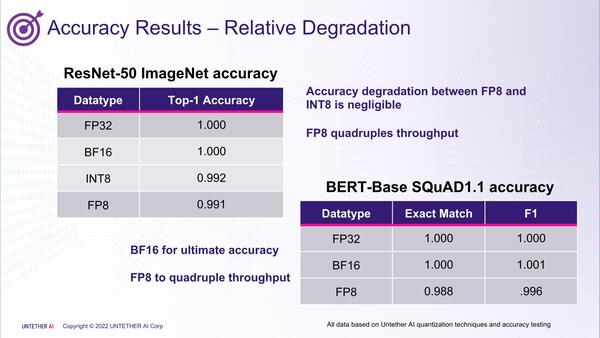
SQuAD(Stanford Question Answering Dataset)は名前の通り質問と回答のデータセット。現在は2.0がリリースされている
ところで先ほど出てきたRISC-Vコアだが、同時4スレッド実行のSMT構成で、ただしカスタム命令の形でPEへの制御が行なえるようになっている。

逆に重い処理をさせるつもりがないので、それぞれのプロセッサーには4KBのSRAMが搭載され、これを利用して処理をすることになる。ただこれで足りるのか? は少しだけ疑問である
一応RISC-Vコアでも計算は可能だが、カスタム命令一覧を見ればわかるように、主目的はPEの制御になるだろう。runAI200では独自コアを用意していたが、PE制御はともかく汎用プロセッサーとしての処理は別に独自色を出す必要はないわけで、開発環境やソフトウェアサポートなどを考えてもRISC-Vをベースに、拡張命令だけをサポートする方向に切り替えたということだと思われる。
Boqueriaもまた、マルチチップ拡張が可能である。前ページにあるBoqueriaの内部構造を示した画像にもあるように、もともとそれぞれのチップは4つのPCIe Gen5 x8レーンを装備しており、これを利用してCard-to-CardおよびChip-to-Chipの直接接続が可能な構成になっているそうだ。
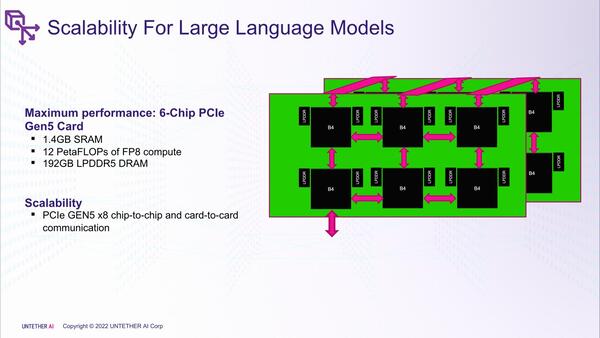
今度はホストとの接続にPCIeスイッチは要らないことになるのだが、帯域的にこれで足りるのだろうか? Boqueriaの構造からして、ホストと煩雑にデータのやり取りをする必要はない気もするが、さすがにカード2枚で12個のBoqueriaを1ポートのPCIe Gen5 x8でカバーするのは厳しい気がする
気になる性能であるが、現時点でまだBoqueriaのサンプルは出てきておらず、下の画像は推定である。にしても、絶対性能で12PFlops、性能/消費電力比で30TFlops/Wというのは相当に強力な数字である。
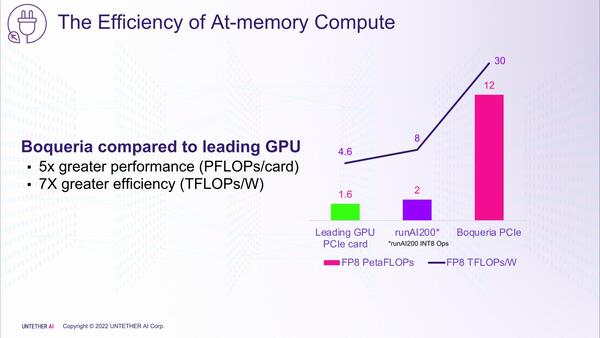
INT4でも同等の数字になるはずだが、INT8だと半分だろうか? それでも6 POPS、15TOPS/Wだからかなり強力だ
まだ推定値ということでアプリケーション性能も相手は“Leading Competitor(競合製品)”で具体的になにかはわからないが、圧倒的な性能と性能/消費電力比を達成できる、というのがUntether AIのメッセージである。

ResNet-50の競合が“37263”とやけに具体的な数字なので探してみたのだが、MLPerf 2.0の公開されているスコアには見つからなかった
ちなみにUntether AIの予定では、2023年前半中にサンプル出荷を始める予定で、その際の商品名はSpeedAI240になるそうだ。これが無事に出荷されると、競合にとってはけっこう戦いにくいことになりそうである。

この連載の記事
-
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ -
第849回
PC
d-MatrixのAIプロセッサーCorsairはNVIDIA GB200に匹敵する性能を600Wの消費電力で実現 -
第848回
PC
消えたTofinoの残響 Intel IPU E2200がつなぐイーサネットの未来 -
第847回
PC
国産プロセッサーのPEZY-SC4sが消費電力わずか212Wで高効率99.2%を記録! 次世代省電力チップの決定版に王手 -
第846回
PC
Eコア288基の次世代Xeon「Clearwater Forest」に見る効率設計の極意 インテル CPUロードマップ -
第845回
PC
最大256MB共有キャッシュ対応で大規模処理も快適! Cuzcoが実現する高性能・拡張自在なRISC-Vプロセッサーの秘密 -
第844回
PC
耐量子暗号対応でセキュリティ強化! IBMのPower11が叶えた高信頼性と高速AI推論 -
第843回
PC
NVIDIAとインテルの協業発表によりGB10のCPUをx86に置き換えた新世代AIチップが登場する? -
第842回
PC
双方向8Tbps伝送の次世代光インターコネクト! AyarLabsのTeraPHYがもたらす革新的光通信の詳細 - この連載の一覧へ


 ゲーミングマウスパッド G240 クロス表面 標準サイズ 340×280×1mm マウスパッド G240f 国内正規品")













を2画面搭載するモバイルディスプレー")























の全国大会を見てきた")







")
 旧東芝メモリ microSD 128GB UHS-I Class10 (最大読出速度100MB/s) Nintendo Switch動作確認済 国内サポート正規品 メーカー保証5年 KLMEA128G")


【日本製】USBフラッシュメモリ 32GB USB2.0 国内サポート正規品 KLU202A032GL")

")
+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
")


