




今回はTachyumのProdigyを取り上げる。ちなみにTachyum自身はProdigyを“World's First Universal Processor”と称しているが、一般的にはAIプロセッサーと扱われており、筆者もこれに準じてAIプロセッサーとして紹介したい。

スロバキアとのつながりが強いTachyum社
創業者のDanilak博士はいろいろなプロセッサーを開発
Tachyumは2016年、Radoslav Danilak博士によって創業された。ちなみに本社そのものはサンタクララに存在するが、同社は限りなくスロバキアとのつながりが強い。Danilak博士自身、アメリカの市民権を持つが生まれはスロバキアであり、現在もスロバキア政府のInnovation Advisory Boardのメンバーを務めてもいる。
そもそもDanilak博士の経歴を見ると、スロバキアのDanSoft SroというVLIWプロセッサーを開発する会社を創業、CEO兼CTOを務める→Gizmo Technologyというx86互換プロセッサーの開発を目指していた会社のChief Architect→東芝でTX7901(MIPSベースのコアで、PS2で使われた)のSr.Staff Processor Architect→nishan systemという会社でネットワークプロセッサーのSr. Processor Architect →nVIDIAでnForce 4/nForce 4 Intel Eedition chipsetのSr Architect→SandForceの創業者兼CTO→ディスクコントローラーを作るSkyeraという会社を創業→同社の買収にともないWDでCTO→Tachyumを創業といった具合に、さまざまな企業を創業してはいろいろなプロセッサーを開発していたそうだ。
また、どうも連載568回で紹介したWave Computingで10GHz駆動のDPU向けプロセッサーエレメントの開発にも関係していたことがあったらしい。
PCIe Gen5とDDR5、HBM3まで搭載する超欲張りセット
VLIWというあたりにItaniumと同じ匂いを感じる
そんなTachyumであるが、2018年のHotChipsで、同社のProdigyチップの詳細を初めて公開した。ProdigyはいくつかのSKUがあるが、ハイエンドは64コア構成となっている。CPUコアと32MBキャッシュ、DDR4/5×8ch、400Gイーサネット、PCIe Gen5 x72と周辺回路も盛り盛りで、さらにオプションでHBM3まで搭載という、超欲張りセットである。

もっとも2018年の時点でPCIe Gen5やDDR5という時点でわりと無茶な気はする。HBM3に至ってはまだ仕様策定も始まっていない
これをTSMCのN7で製造し、全コア4GHz駆動で消費電力がたったの180Wというのは、もう「僕の考えた最強(最狂?)CPU」という感じで、シミュレーションの数字なのか願望なのか外部からは判断できない。
なぜこれが実現できるか? と言えば、個々のコアが「Armコアより小さく、Xeonより高速に動作するから」であるが、その理由の1つが「Out-of-Order execution with Compiler」というあたりに、Itaniumと同じ匂いを感じてしまう。
ちなみに設計は一切カスタム設計はなく、TSMCのStandard CellとSRAMで構成され、配置配線もEDAによる自動配線で設計しており、それでダイサイズは290mm2というから、かなりコアそのものは小さいということになる。
そのコアの命令セットが下の画像だ。最大4命令をバンドルできる、というあたりでVLIWであることは確定である。内部ではさらにこれをmicro-opに変換するようで、最大8 micro-opsのVLIWということになる。
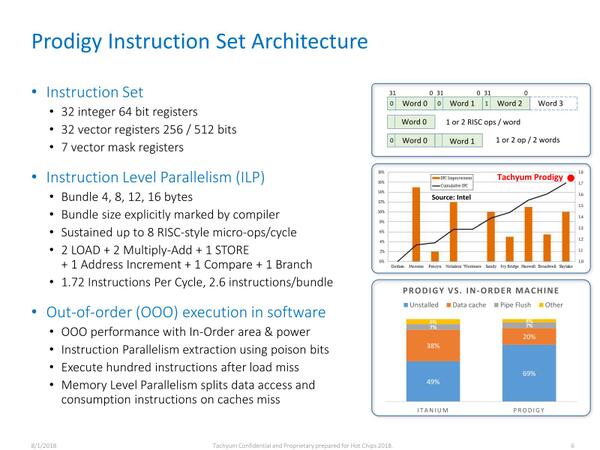
中央のグラフは、左軸が縦棒(前世代からのIPC向上率)、右軸が折れ線(累積でのIPC向上率)で、Dothan世代が基準らしいが、ProdigyはSkylakeより少しマシ程度、ということになる。もっともアーキテクチャーが異なるので、この比較に意味があるのかは謎だ
もっとも命令そのもので言えば、演算はMAC×2で、あとはLoad/Store/Compare/Branchなどが占めていることを考えると、そんなに極端に演算処理に振っているわけでもない。Prodigyではこの1~4命令をまとめた物をBundleと称しているが、1命令がおよそ1.72 micro-op相当、1 Bundleが2.6 micro-op相当なので、VLIWといっても無理やりにIPCを引き上げている感じはしない。
このあたりはむしろ堅実な設計という気はするのだが、それをすべてぶち壊している感じがするのが“Out-of-order execution in software”である。コンパイラ屋さんが憤死しそうな話ではあるが、要するに
- VLIW方式なのでデコードが非常にシンプルであり、余分な動作が入らない
- 命令実行はハードウェア的にはIn-Orderなので、処理コストのかかるDispatcherやSchedulerが不要になる
In-Orderがゆえに通常問題になる、データ待ちによるPipeline Stallなどは、コンパイラの側で対応するので(←これがわりと無茶)、ハードウェア的に余分な機構を用意せずに高効率で実行できる。
ということで、Armに比べてもはるかに小さい回路サイズで実現が可能であり、回路サイズが小さいということは動作周波数を上げやすいということになる。とりあえずコンパイラ屋さんの苦悩を無視すれば、これは理解できる方針である。そのコンパイラがしばしば仇になることが多いのがVLIWの歴史でもあるのだが。
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ

")

")
 /Windows11 Pro/MS Office2019/WIFI内蔵/Webカメラ/DVD-ROM/テンキー/Bluetooth/HDMI(Corei5-8265U,メモリ8GB,SSD256GB)")










実機レビュー")
実機レビュー")








 旧東芝メモリ microSD 128GB UHS-I Class10 (最大読出速度100MB/s) Nintendo Switch動作確認済 国内サポート正規品 メーカー保証5年 KLMEA128G")
")
【日本製】USBフラッシュメモリ 32GB USB2.0 国内サポート正規品 KLU202A032GL")

: 11 インチモデル、Liquid Retina ディスプレイ、128GB、Wi-Fi 6、12MP フロント/12MP バックカメラ、Touch ID、一日中使えるバ ッテリー - シルバー")
")

【日本製】SDカード 128GB SDXC UHS-I Class10 読出速度100MB/s 国内正規品 メーカー保証5年 KLNEA128G")
")
/iPad 各種対応(ダークグレー 0.9m)")

