




ネットワーク向けのASICは
AI向けプロセッサーに応用が利く
そんなネットワーク向けのASICは端的に言えばなにをするか、というのが下の画像だ。要するに複数のポートから間欠的に入ってくるパケットの素性を迅速に確認し、処理の優先順位を決めて、かつ目的地に送り出す、というのが最大の処理になる。
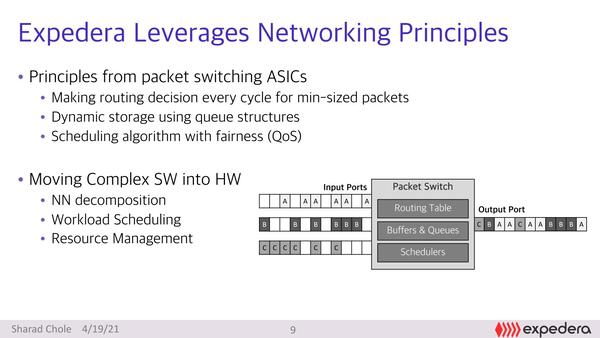
ネットワーク向けASICの処理内容。難しいのは、L2 スイッチであればイーサネットのMACアドレスだけで判断できるが、L3ならIPアドレスでの判断になり、L4以上のスイッチではプロトコルまで見る必要が出てくることで、短い時間でパケットの中身を解析して、それに応じて処理する必要がある
実はこれ、かなりAI向けプロセッサーに応用が利く、というのが同社の説明である。画像データを連続的に取り込んでネットワークに掛け、ネットワークの各段で畳み込み演算を大量に行なって最終的な推論結果を得る、というのがAI、というより畳み込みニューラルネットワーク(CNN)の基本となる。
ここでSparsity、つまりデータが疎の場合には演算しても無駄になるので、どれだけ疎の部分の処理を省けるか、というのが畳み込みニューラルネットワークの処理効率を引き上げる場合のキーになるというのは、過去の連載で説明してきた通り。
そこでデータフローや非同期などいろいろな策を講じてきているが、同社によればこの「疎の部分」というのは、ネットワーク向けASICで言えば「パケットが届いていないタイミング」に相当するというわけだ。
上の写真の図に戻ると、図の左側の「Input Ports」にA/B/Cの3つのパケットの流れがあるが、連続しているわけではなくしばしば空白部分がある。これはネットワークASICでは避けられないもので、これをうまくパケットスイッチの中でスケジューリングすることでOutput Port側ではパケットが密に詰まった格好で出てくる。
同じことを畳み込みニューラルネットワークにも適用すればいいわけだ。つまり疎の部分を含んだデータをそのまま畳み込み演算に掛けるのではなく、一度スケジューリングして必要な演算だけを連続して行なえるように並び替えできれば、畳み込み演算の効率を最大限にできる、というのが基本的な同社の発想である。
同社のOriginシリーズの基本的な構成は以下の通り。最大の特徴は、複数ある演算ユニットがすべてDecoupled(分離)されていることだ。Global Interconnectも一切存在しない、というあたりはこれまでのプロセッサーとかなり内部構造が異なる。
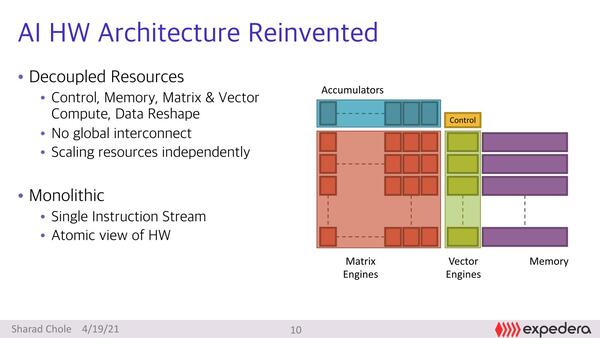
現状はそれぞれのユニットの詳細の説明がないので詳しいことはわからないのだが、おそらくはMatrix Engineが畳み込み、Accumulatorsがその後の加算、Vector Engineがその他特殊演算向けといったところだろう
それぞれのユニットやメモリーの容量などは完全に独立してスケーリングするあたりは、畳み込み処理を実施する前に、前述の図のPacket Switchにあたる部分で完全にスケジューリングし、それぞれの処理での依存関係を完全に解消した上でMatrix Engineに渡し、そこからAccumulatorsに引き渡され、最終的にメモリーに入る(あるいは、Vector Engine経由でメモリーに入る)という形を想定しているらしい。
個々の演算ユニットは比較的深いパイプライン構造になっており、シーケンシャルに処理される。上で書いたように、個々の処理の依存関係を完全に解消させた上で処理をスタートしているため、同期を取ったり、値を戻したりする必要がないので、演算ユニットそのものは極めてシンプルである。またコンテキストスイッチングはDeterministic(決定論的:あらかじめコンテキストスイッチングのタイミングを決めて実施する方式)なので、ペナルティーなしで実行できる。
ここで、各々の処理が1サイクルで終わらないのがおそらくはミソである。expederaは、前回も主張したように性能はIPS/W、つまり1Wあたりの推論性能で測定すべしとしている。そのためには、個々の処理ユニットが高性能なだけでなく、高効率である必要がある。
1サイクルで個々の処理が終わるような構造にすることはもちろん可能だろうが、それだけ回路が複雑化して速度を上げにくいし、無理に速度を上げるためには電圧を上げる必要があるため省電力にはならない。むしろなるべくシンプルにして、パイプライン段数も深くした方が、1段あたりの回路も減って省電力化させやすい。
パイプラインを深くするとパイプラインハザードやパイプラインストールなどでの性能へのペナルティーが大きくなるが、今回の構成ではそもそもハザードやストールが発生しないので、これを無視できるわけだ。
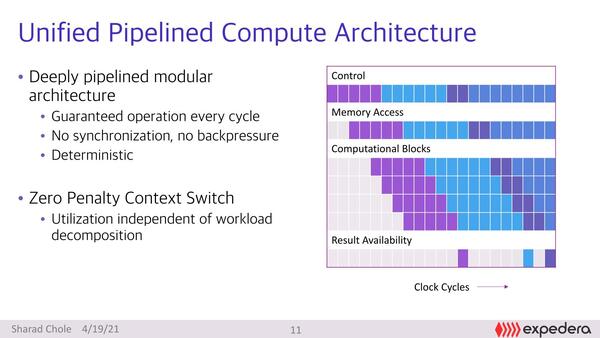
正確に言えばコンテキストスイッチングのペナルティーそのものがゼロになることはないはずだが、Deterministicということはコンテキストスイッチングにともなうリソースの退避などは事前にできる。スイッチング後のパイプラインのフラッシュも行なわれない(事前に次のコンテキストの内容をパイプラインに詰められる)ので、結果としてペナルティゼロに見えるのだろう
ただ、依存関係の解消を含むスケジューリングの制御はけっこう難しい。それもあってこれをソフトウェアでやってしまえ、と決断した結果は、例えばIntel 860やItanium系列のように、思ったように性能が出ないことになる。expederaはこれを完全にハードウェアで行なったというのがポイントである。
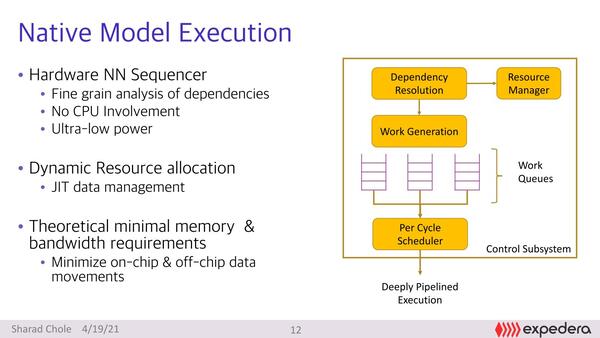
スケジューリングの制御をソフトウェアではなくハードウェアで行なうのがexpederaの特徴。2つ前の画像でポツンとあるControlブロックがそれである
この実装のノウハウは、ネットワーク向けASICの実装の中で培われてきたものだそうで、このあたりが他社との差別化の最大のポイントということになる。そしてこれをハードウェアで実装できたので、さまざまなネットワークへの対応も容易としている。
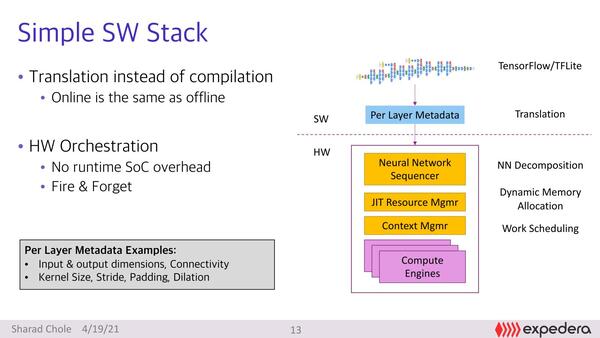
コンパイルではなくトランスレートというのがポイント。それにしてもFire&Forget(撃ちっぱなしミサイル:撃つとミサイルが自動で敵を追尾するので、射手が発射後に誘導する必要がない)というのは言い得て妙というか、なんというか
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ


/ ACアダプター付属/初期設定済み・届いてすぐ使用可能/ 180日保証")


/Windows11 Pro/MS Office 2021搭載/Webカメラ/Wifi/Bluetooth/HDMI/Type-C/ワイヤレスマウス付(メモリ8GB, SSD256GB)")













実機レビュー")
実機レビュー")








+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
/3.1(Gen 1)/3.0/2.0 RUF3-K64GA-BK/N")

 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")

")




