




フラッシュメモリーを流用して
Analog Computerに仕立て上げる
もう1つは、データは移動してナンボという話である。自分の計算結果をそのまま次の演算で使う場合には、この方式は極めて効率が良い。ところが、それこそAI推論のように毎サイクル異なるデータの演算を行なう場合、結果としてデータのメモリー間移動が発生することは避けられない。つまり
メモリー→キャッシュ→レジスター→演算器→(計算)→レジスター→キャッシュ→メモリー
という流れが、以下に削減されるだけである。
メモリー→キャッシュ→演算セル→(計算)→キャッシュ→メモリー
この場合、メモリー→キャッシュやキャッシュ→レジスターあるいは演算セルのデータ移動の消費電力がはるかに大きいので、レジスターを減らすことで消費電力を多少減らせるとしても、それほど大きいものではない。
少なくともIn-Memory Computingを採用することで複雑化する内部構造や演算の制約などのデメリットに見合うだけの消費電力削減効果は期待できないということだ。
これをMythicはどうしたか? という話はあとに回すとして、最大のポイントがAnalog Computingである。Mythicは2018年のHot Chips 30において“Analog Computation in Flash Memory for Datacenter-scale AI Inference in a Small Chip”という講演を行なっているが、彼らのアイディアは2次元構造にしたフラッシュメモリーを流用して、そのままこれをAnalog Computerに仕立て上げるというものだ。
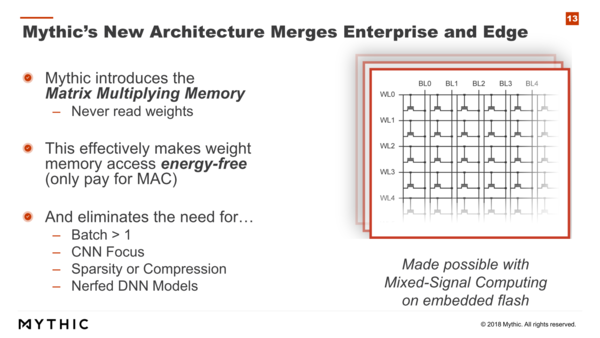
このMatrix Multiplying Memoryは富士通の40nmフラッシュプロセスで製造されたとのこと
以前V-NANDの解説に絡んでフラッシュメモリーの構造を解説したことがあるが、Floating Gateと呼ばれる領域に電荷をため込むことで、これをメモリーセルとして利用する方式である。
構造そのものは、WL(Word Line)とBL(Bit Line)の交点にFloating Gateのセルを1つずつ置く形である。このセルに、ネットワークの重みをあらかじめロードしておく。つまりこのMatrix Multiplying Memoryと呼ばれるものは、これそのものがネットワークの重みを格納できるメモリーになるわけだ。
さて、このセルは可変抵抗として扱える。セルとはいっても構造的にはMOSFETであり、MOSFETはVds(ドレイン/ソース間電圧)がVgs-Vth(ゲート/ソース間電圧-閾値電圧)より低い間は、線形の抵抗として機能する。すると、オームの法則(電圧=電流×抵抗)を変形させて(電流=電圧÷抵抗)利用して乗算と加算ができることになる。
入力データはDAC(Digital Analog Converter)を利用して値を電圧に変換して、Matrix Multiplying Memoryにかけてやると、それぞれのメモリーセルの値の逆数に比例する電流が斜め方向に流れることになる。これが乗算だ。
そして最終的にADCで受けるのは、複数のセルから流れてきた電流の合計値であるから、ここで加算ができることになる。
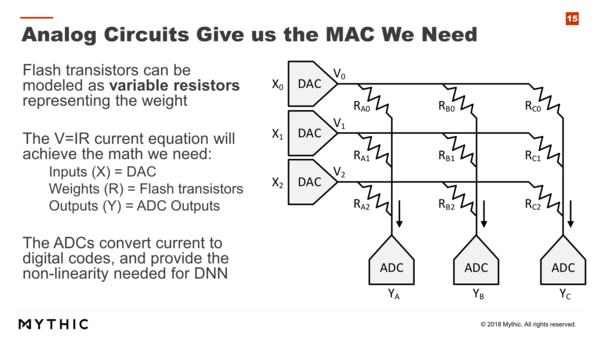
DAC/ADCに関してもやはり8bit程度の精度が必要になるため、これがそれなりの面積を喰うが、M1108に関してはDACではなくデジタルの近似回路を利用しており、将来のバージョンではここもちゃんとDACにする予定という話であった
ここで問題になるのはR、つまり個々のメモリーセルを利用した抵抗の精度である。SLCだと0か1の1bit、MLC/TLC/QLCでもそれぞれ2/3/4bitだから、最大でも16レベルでしかない。ただこれはMLC/TLC/QLCと同じく、継ぎ足しを行なえばもっと多値化が可能になる。
実際Mythicでは8bit演算を可能にしているから256レベルの値を保持できることになる。もっともさすがにこれを1個のメモリーセルで実現するのは難しいので、Mythicでは2つのメモリーセルをペアにし、2つのセルの値の差で-128~+128までを保持するようにしている。
こういうことをするとメモリーセルの寿命が気になるかもしれないが、フラッシュメモリーそのものと違い、そもそも書き込みを煩雑におこなったりする使い方ではない。端的に言えば、あるネットワークをロードするときに1回、それぞれのWeightをロードしたら、別のネットワークをロードするまでの間、そのセルを書き換える必要がないからだ。
もちろん大規模なネットワークを無理やりロードしようとしたら、毎回メモリーセルの内容を書き換える必要があり、これはおそらくメモリーセルの寿命を加速度的に縮めることになる。ただMythicのIPUはそこまで大規模なネットワークを扱う予定はないし、そもそも演算器といってもただのフラッシュメモリーだから、通常のプロセッサーよりもはるかに高い演算密度を実現できる。
この連載の記事
-
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 -
第853回
PC
7つのカメラと高度な6DOF・Depthセンサー搭載、Meta Orionが切り開く没入感抜群の新ARスマートグラス技術 -
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ - この連載の一覧へ


/ ACアダプター付属/初期設定済み・届いてすぐ使用可能/ 180日保証")


/Windows11 Pro/MS Office 2021搭載/Webカメラ/Wifi/Bluetooth/HDMI/Type-C/ワイヤレスマウス付(メモリ8GB, SSD256GB)")













実機レビュー")
実機レビュー")








+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
/3.1(Gen 1)/3.0/2.0 RUF3-K64GA-BK/N")

 2025 用/iPad 第10世代 2022 用 10.9インチ フイルム ガイド枠付き 強化 ガラス 保護フイルム あいぱっど 11世代/10世代 対応 NTB22I574 1枚")

")




