




CPU性能の向上で第1期のプランが実現可能に
3度目の興隆は、1993年頃から始まった。きっかけは急速なCPU性能の向上であり、1回目の興隆の際には「処理が遅すぎて使い物にならない」と判断されたアルゴリズムや実装が、この頃になると「そこそこの速度で動く」ことになり、再びAI研究者がアルゴリズムの再検討や新しいアルゴリズムの開発などを始めるようになってきた。
特に2007年にNVIDIAがCUDAを発表して以降、GPUを使ってAI向けの処理を行なうという方法が次第にポピュラーになってきた。
これを後押しした有名な論文が、Natureに1986年10月に掲載された“Learning representations by back-propagating errors”である。それまで、人間の神経細胞を模した形でニューロンとシナプスのネットワークを構築するにあたっては、ニューロンの「発火」(あるしきい値を超えてニューロンが神経パルスを生じさせること)をどれだけ忠実に実現できるか(orほかの形でモデリングできるか)に腐心していた。
これもあって初期のAIではコンピューター科学というよりは、なかば生理学や心理学、神経科学などの学者が多く参画していた。ところがこの論文では、そうした生化学的なモデルはとりあえず脇において、計算科学で良く利用される勾配法という手法を使っても、結果としてうまく行くことを証明した。
この論文以降、AIの中でもNN(Neural Network)と呼ばれる、人間の神経細胞を模したモデルに関しては、心理学あるいは生理学から離れ、純粋に計算機科学で完結するようになり始めた。
AIの画像認識の精度が人間を超える
決定的にNNが3度目のAIで主流になったのは、2012年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)の2012年における、トロント大学のImageNetである。
ILSVRCは、画像認識の精度を競うチャレンジであり、具体的には与えられた画像から正しく対象物を検出(Detection)し、分類(Classification)/位置判別(Location)できるかどうか、を評価する。

1枚の画像から、人物(4人)と犬(1匹)を正しく識別し、かつその位置をきちんと判断できるかどうか(CLS-LOC:Classification-Location)の比較例。それ以外に、そもそも画像から正しく対象を検出できるか(Detection)の評価もある
対象物もけっこういろいろあり、検出の場合は200種類、分類/位置判別は1000種類の対象物が用意される。このILSVRCの2012年のチャレンジで、トロント大学は5層の畳み込み(Convolution)と、3層の畳み込みから構成されるAlexNetというNNを提案した。
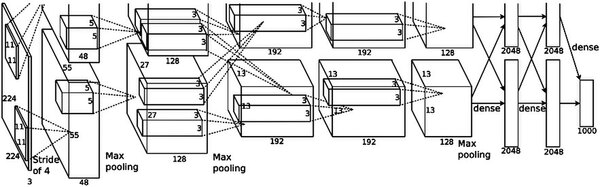
まず最初に5つの畳み込み層(うち1・2・5層目ではMax Poolingを併用)、その後2層の全結合層を経て結果が出力される。ちなみにそれぞれのニューロンの数は第1層が25万3400個、第2層が18万6624個、以下6万4896個、6万4896個、4万3264個、4096個、4096個、1000個で合計62万2000個強のニューロンを利用している
このImage Netが、エラー率16.4%という驚異的に低い数値を叩き出したことで、俄然NN(それも畳み込みを使ったCNN:Convolutional Neural Network)に注目が集まった。なにせその前年はXeronのものが25.8%、さらに前年はNECとUIUC(イリノイ大学アーバナ・シャンペーン校)の共同チームが28.2%というエラー率でそれぞれ優勝している。
特にNEC-UIUCはSparse codingとMax poolingという手法を組み合わせた方法で、画像をグレースケール化して識別しているにも関わらず、カラーのパターン認識よりもずっと高性能ということでかなり注目を集めた手法だったが、トロント大学のAlexNetはこれを10%以上改善する結果を見せたことに加え、より層数を増やせばより精度が上がる見込みだと語ったことで、さまざまな研究機関が一斉にCNNに向かって走り出す。
翌年はClarifaiというネットワーク(8層モデル)がエラー率11.7%、2014年はGoogleが22層のGoogle Netで6.67%、2015年にはMicrosoft Researchが152層ものネットワーク(ResNet)でついに3.57%を達成する。
実は一般人に同じ作業をさせると、平均5.1%ほどのエラー率となる。というのは、当然入り組んだ画像になると、見落としや見間違いが避けられないからで、この2015年のResNetでついにAIが人間を超えたと評された。
この連載の記事
-
第852回
PC
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現 -
第851回
PC
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ -
第850回
デジタル
Zen 6+Zen 6c、そしてZen 7へ! EPYCは256コアへ向かう AMD CPUロードマップ -
第849回
PC
d-MatrixのAIプロセッサーCorsairはNVIDIA GB200に匹敵する性能を600Wの消費電力で実現 -
第848回
PC
消えたTofinoの残響 Intel IPU E2200がつなぐイーサネットの未来 -
第847回
PC
国産プロセッサーのPEZY-SC4sが消費電力わずか212Wで高効率99.2%を記録! 次世代省電力チップの決定版に王手 -
第846回
PC
Eコア288基の次世代Xeon「Clearwater Forest」に見る効率設計の極意 インテル CPUロードマップ -
第845回
PC
最大256MB共有キャッシュ対応で大規模処理も快適! Cuzcoが実現する高性能・拡張自在なRISC-Vプロセッサーの秘密 -
第844回
PC
耐量子暗号対応でセキュリティ強化! IBMのPower11が叶えた高信頼性と高速AI推論 -
第843回
PC
NVIDIAとインテルの協業発表によりGB10のCPUをx86に置き換えた新世代AIチップが登場する? -
第842回
PC
双方向8Tbps伝送の次世代光インターコネクト! AyarLabsのTeraPHYがもたらす革新的光通信の詳細 - この連載の一覧へ


 ゲーミングマウスパッド G240 クロス表面 標準サイズ 340×280×1mm マウスパッド G240f 国内正規品")













を2画面搭載するモバイルディスプレー")























の全国大会を見てきた")







")
 旧東芝メモリ microSD 128GB UHS-I Class10 (最大読出速度100MB/s) Nintendo Switch動作確認済 国内サポート正規品 メーカー保証5年 KLMEA128G")


")
+380 5色マルチパック BCI-381+380/5MP 長さ:5.3cm 幅:13.9cm 高さ:10.75cm")
")
【日本製】USBフラッシュメモリ 32GB USB2.0 国内サポート正規品 KLU202A032GL")



